目录
一、文件格式
1.1 列式存储和行式存储
1.1.1 行存储的特点
1.1.2 列存储的特点
1.2 TextFile
1.3 SequenceFile
1.4 Parquet
1.5 ORC
二、数据压缩
2.1 数据压缩-概述
2.1.1 压缩的优点
2.1.2 压缩的缺点
2.2 Hive中压缩配置
2.2.1 开启Map输出阶段压缩(MR 引擎)
2.2.2 开启Reduce输出阶段压缩
2.3 Hive中压缩测试
一、文件格式
Hive数据存储的本质还是HDFS,所有的数据读写都基于HDFS的文件来实现。为了提高对HDFS文件读写的性能,Hive提供了多种文件存储格式:TextFile、SequenceFile、ORC、Parquet等。不同的文件存储格式具有不同的存储特点,有的可以降低存储空间(列式存储),有的可以提高查询性能(行式存储)。Hive的文件格式在建表时指定,默认是TextFile。
1.1 列式存储和行式存储
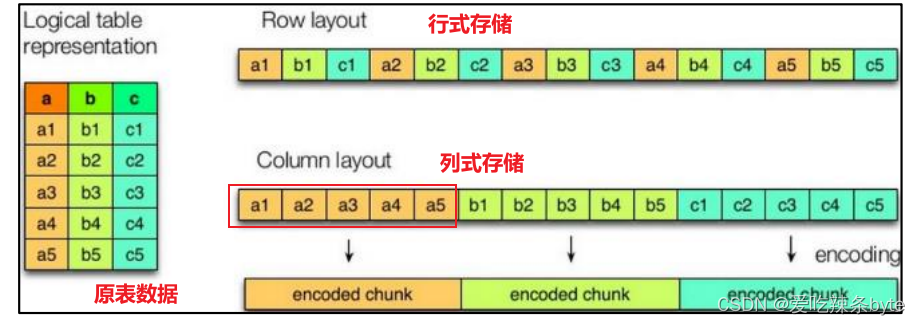
1.1.1 行存储的特点
查询满足条件的一整行数据的时候,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
1.1.2 列存储的特点
每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。TextFile和 SequenceFile的存储格式都是基于行存储的,ORC和Parquet是基于列式存储的。
1.2 TextFile
TextFile是Hive中默认的文件格式,也是最常见的数据文件格式,存储形式为按行存储。Hive设计时考虑到为了避免各种编码及数据错乱的问题,选用了TextFile作为默认的格式。建表时不指定存储格式即为TextFile,导入数据时把数据文件拷贝至HDFS不进行处理。

1.3 SequenceFile
SequenceFile是Hadoop里用来存储序列化的键值对,即二进制的一种文件格式。SequenceFile文件也可以作为MapReduce作业的输入和输出,hive也支持这种格式。

--sequencefile表
create table tb_sogou_seq(
stime string,
userid string,
keyword string,
clickorder string,
url string
)
row format delimited fields terminated by '\t'
stored as sequencefile;
insert into table tb_sogou_seq
select * from tb_sogou_source; -- tb_sogou_source表 是txt文件格式下图是插入原始txt文件(tb_sogou_source)大概有1.07G1260万条数据存储成SequenceFile的文件大小。

1.4 Parquet
Parquet是一种支持嵌套结构的列式存储文件格式。作为大数据系统中OLAP查询的优化方案,它已经被多种查询引擎原生支持,并且部分高性能引擎将其作为默认的文件存储格式。

--Parquet格式
create table tb_sogou_parquet(
stime string,
userid string,
keyword string,
clickorder string,
url string
)
row format delimited fields terminated by '\t'
stored as parquet;
insert into table tb_sogou_parquet
select * from tb_sogou_source; -- tb_sogou_source表 是txt文件格式下面图示是插入原始txt文件(tb_sogou_source)大概有1.07G1260万条数据存储成Parquet的文件大小。
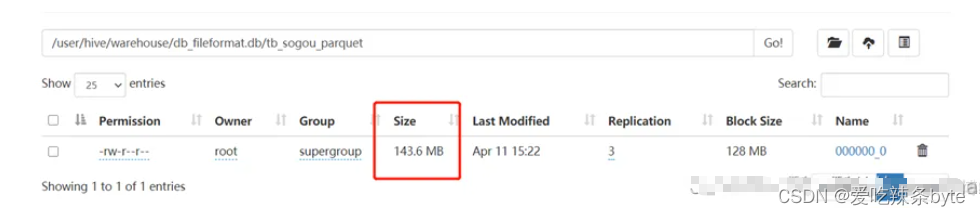
1.5 ORC
ORC(OptimizedRC File)文件格式也是一种Hadoop生态圈中的列式存储格式;它最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。

--ORC格式
create table tb_sogou_orc(
stime string,
userid string,
keyword string,
clickorder string,
url string
)
row format delimited fields terminated by '\t'
stored as orc;
insert into table tb_sogou_orc
select * from tb_sogou_source;下面图示是插入原始txt文件(tb_sogou_source)大概有1.07G1260万条数据存储成ORC的文件大小。

二、数据压缩
2.1 数据压缩-概述
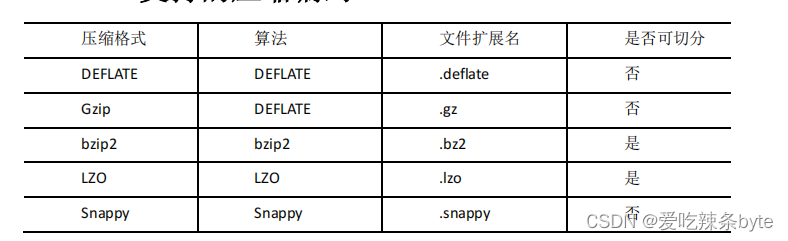
Hive压缩实际上说的就是MapReduce的压缩。Hive底层运行MapReduce程序时,磁盘I/O操作、网络数据传输、shuffle(清洗)和merge(合并)要花大量的时间,尤其是数据规模很大和工作负载密集的情况下。鉴于磁盘I/O和网络带宽是Hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘I/O和网络传输非常有帮助。MR 支持的压缩算法如下:
2.1.1 压缩的优点
- 减小文件存储所占空间
- 加快文件传输效率,从而提高系统的处理速度
- 降低IO读写的次数
2.1.2 压缩的缺点
- 使用数据时需要先对文件解压,加重CPU负荷,压缩算法越复杂,解压时间越长
- Hive中的压缩就是使用了Hadoop中的压缩实现的,所以Hadoop中支持的压缩在Hive中都可以直接使用。
2.2 Hive中压缩配置
2.2.1 开启Map输出阶段压缩(MR 引擎)
开启map输出阶段的压缩可以减少map和Reduce task间数据传输量。具体参数有:
--开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
--开启mapreduce中map输出端的压缩功能
set mapreduce.map.output.compress=true;
--设置mapreduce中map输出端的数据的压缩方式
set mapreduce.map.output.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;2.2.2 开启Reduce输出阶段压缩
当 Hive将执行结果写入到表中时,输出内容同样可以进行压缩。其余参数如下:
#当Hive将输出内容写入到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output控制着这个功能
--开启hive执行结果的输出压缩功能
set hive.exec.compress.output=true;
---开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
---设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
---设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
2.3 Hive中压缩测试
- textfile格式snappy压缩
--创建表,指定为textfile格式,并使用snappy压缩
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as textfile
tblproperties("orc.compress"="SNAPPY");
- orc格式snappy压缩
--创建表,指定为orc格式,并使用snappy压缩
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="SNAPPY");
- orc格式不使用压缩
--创建表,指定为orc格式,并使用snappy压缩
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="NONE");![[OPEN SQL] 修改数据](https://img-blog.csdnimg.cn/direct/a275ec0c8bb44cae93bbd67bb39bb922.png)